엑셀 / 함수 / FIND, FINDB, SEARCH, SEARCHB / 특정 문자열의 시작 위치를 반환하는 함수
개요
- FIND, FINDB, SEARCH, SEARCHB는 특정 문자열의 시작 위치를 반환하는 함수입니다.
- FIND, FINDB는 대소문자를 구분합니다.
- SEARCH, SEARCHB는 대소문자를 구분하지 않습니다.
- FIND와 SEARCH는 글자 수 기준으로, FINDB와 SEARCHB는 바이트 기준으로 계산합니다.
구문
FIND(find_text, within_text, [start_num]) FINDB(find_text, within_text, [start_num]) SEARCH(find_text, within_text, [start_num]) SEARCHB(find_text, within_text, [start_num])
- find_text : 필수 요소로, 찾으려는 문자열입니다.
- within_text : 필수 요소로, 찾을 대상이 되는 문자열입니다.
- start_num : 선택 요소로, 검색을 시작할 위치입니다. 생략하면 1로 간주합니다.
find_text가 within_text에 없으면 #VALUE!을 반환합니다.
start_num이 0보다 크지 않으면 #VALUE!을 반환합니다.
start_num이 within_text의 길이보다 길면 #VALUE!을 반환합니다.
예제
FIND와 FINDB의 예제입니다. 대소문자를 구분하지 않고 싶다면 FIND는 SEARCH로, FINDB는 SEARCHB로 변경합니다.
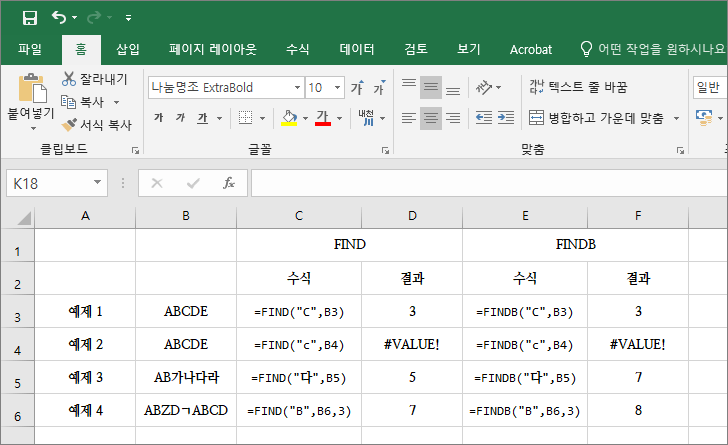
예제 1
- 'ABCDE'에서 'C'의 시작 위치를 찾습니다.
- 더블바이트 문자가 아니므로 FIND와 FINDB의 결과가 같습니다.
- 세번째에 'C'가 있으므로 3을 반환합니다.
예제 2
- 'ABCDE'에서 'c'의 시작 위치를 찾습니다.
- 더블바이트 문자가 아니므로 FIND와 FINDB의 결과가 같습니다.
- 소문자 'c'가 없으므로 #VALUE!를 반환합니다.
예제 3
- 'AB가나다라'에서 '다'의 시작 위치를 찾습니다.
- FIND는 더블바이트 문자도 1로 계산하므로 5를 반환합니다.
- FINDB는 더블바이트 문자를 2로 계산하므로 7을 반환합니다.
예제 4
- 'ABCDㄱABCD'에서 B의 시작 위치를 찾습니다. 세번째 인수에 3이 있으므로 Z부터 찾습니다.
- FIND는 ㄱ을 1로 계산하므로 7을, FINDB는 ㄱ을 2로 계산하므로 8을 반환합니다.
엑셀 / 함수 / AVERAGE, AVERAGEIF, AVERAGEIFS / 산술평균 구하는 함수
개요 AVERAGE는 산술평균을 구하는 함수이다. 특정 조건에 맞는 값들의 산술평균을 구하고 싶다면 AVERAGEIF 또는 AVERAGEIFS 함수를 사용한다. AVERAGE 구문 AVERAGEA(value1, , ...) value1은 필수 요소이고, 이후의 value는 선택 요소이다. 평균을 구하려는 셀, 셀 범위 또는 값으로, 1개에서 255개까지 지정할 수 있다. 예제 예제 1 1, 2, 3의 산술평균을 구한다. 예제 2 1, 2의 산술평균을 구한다. 범위에 문자가 포함된 경우 무시한다. AVERAGEIF 구문 AVERAGEIF(range, criteria, ) range ...
엑셀은 PDF 저장 기능을 갖고 있습니다. Acrobat 등 PDF 변환 프로그램을 설치하지 않아도 PDF 형식의 문서로 변환할 수 있습니다. PDF로 저장하는 방법은 두 가지가 있는데, 하나는 을 이용하는 게 더 편합니다. F12를 눌러서 창을 엽니다. 파일 형식을 PDF로 ...
엑셀로 산술평균, 기하평균, 조화평균을 구할 수 있습니다. 사용하는 함수는 다음과 같습니다. 산술평균 : AVERAGE 기하평균 : GEOMEAN 조화평균 : HARMEAN 아래는 각각의 평균을 구하는 간단한 예제입니다. 아래는 위 예제에 대한 수식입니다.
연말이 되면 여기저기서 달력을 받습니다. 고전적인 것도 있고 예쁜 것도 있습니다. 하지만 100% 마음에 드는 것은 없습니다. 그래서 엑셀로 나만의 달력을 만들었습니다. 달력을 만들 때 가장 귀찮은 것은 날짜를 채우는 것입니다. 날짜만 입력하면 나머지는 모양을 꾸미는 것이므로 어렵지 않습니다. 그렇다면 어떻게 날짜를 채울까요? 가로로 요일을 씁니다. 일요일 밑에 날짜를 입력합니다. 가로 방향으로 드래그하여 날짜를 ...
보기 좋게 표를 만들거나 보고서를 만들려면 셀들을 합쳐야 할 때가 있습니다. 엑셀에서는 셀을 합치는 것을 병합이라고 하고, 다시 나누는 것을 분할이라고 합니다. 어떻게 병합하고 분할하는지, 병합에는 어떤 방법이 있는지 알아보겠습니다. 병합하고 가운데 맞춤 셀을 합치는 가장 간단한 방법은 합치려는 셀들을 선택하고 을 클릭하는 것입니다. 셀들이 하나도 합쳐지고, 텍스트는 가운데 정렬합니다. 셀 병합을 하면 ...
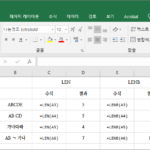
엑셀 / 함수 / LEN, LENB / 문자열의 문자 수, 바이트 수 구하는 함수
개요 LEN은 문자열의 문자 수를, LENB는 문자열의 바이트 수를 구하는 함수입니다. 구문 LEN(text) LENB(text) text : 필수 요소로, 길이를 구하려는 문자열입니다. 공백은 1개의 문자, 1바이트의 문자로 계산합니다. 한국어, 일본어, 중국어는 한 문자를 2바이트로 계산합니다. 예를 들어 LEN("가")는 1, LENB("가")는 2입니다. 예제 예제 1 ABCDE는 모두 1바이트 문자이므로, LEN과 LENB 모두 5를 반환합니다. 예제 2 공백은 1개의 문자, 1바이트 문자로 계산합니다. 예제 3 한국어, 일본어, 중국어는 1개의 문자를 ...
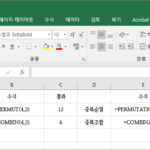
엑셀 / 순열의 수, 중복순열의 수, 조합의 수, 중복조합의 수 계산하기
경우의 수 구하는 함수 엑셀로 순열의 수, 중복순열의 수, 조합의 수, 중복조합의 수를 계산할 수 있습니다. 순열의 수는 PERMUT 함수로, 중복순열의 수는 PERMUTATIONA 함수로, 조합의 수는 COMBIN 함수로, 중복조합의 수는 COMBINA 함수로 구합니다. 구문 PERMUT(number, number_chosen) PERMUTATIONA(number, number_chosen) COMBIN(number, number_chosen) COMBIN(number, number_chosen) number : 필수 요소로, 항목 수입니다. number_chosen : 필수 요소로, 각 경우의 수에 포함되는 항목 수입니다. 순열의 수, 중복순열의 ...
엑셀 / 행의 최대 개수, 열의 최대 개수, 셀의 최대 개수
행, 열, 셀 엑셀은 표 형태로 되어 있어요. 가로를 행이라 하고, 세로를 열이라 하고, 각 칸을 셀이라 합니다. 행은 숫자로 구분하고, 열은 문자로 구분해요. 셀은 열과 행의 이름을 합하여 나타냅니다. 예를 들어 D3는 D열과 3행이 만나는 셀을 의미합니다. 사용할 수 있는 행과 열의 개수는 정해져있어요. 꽤 많긴 하지만 무한대로 있지는 않아요. 최대 몇 ...
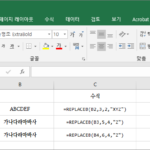
엑셀 / 함수 / REPLACE, REPLACEB / 특정 위치의 문자열을 바꾸는 함수
개요 REPLACE와 REPLACEB는 특정 위치의 문자열을 다른 문자열로 바꾸는 함수입니다. 특정 위치를 찾을 때 REPLACE 함수는 글자 수를 기준으로 하고, REPLACEB 함수는 바이트를 기준으로 합니다. 따라서 한 글자를 2바이트로 계산하는 한국어, 일본어, 중국어에서 차이가 납니다. 구문 REPLACE REPLACE(old_text, start_num, num_chars, new_text) old_text : 필수 요소로, 문자를 바꿀 문자열입니다. start_num : 필수 요소로, old_text에서 new_text로 바꿀 문자의 위치입니다. num_chars : 필수 요소로, old_text에서 사라질 문자의 ...
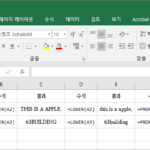
엑셀 / 함수 / UPPER, LOWER, PROPER / 대문자로 또는 소문자로 변환하는 함수
개요 UPPER, LOWER, PROPER는 대문자 또는 소문자 변환과 관련된 함수입니다. UPPER : 모두 대문자(upper case)로 바꿉니다. LOWER : 모두 소문자(lower case)로 바꿉니다. PROPER : 단어의 첫글자는 대문자로, 나머지는 소문자로 바꿉니다. 구문 UPPER(text) LOWER(text) PROPER(text) text : 필수 요소로, 대문자로 또는 소문자로 변환할 텍스트입니다. PROPER 함수 단어의 첫째 문자를 대문자로 변환하고, 나머지 문자들은 소문자로 변환합니다. 예를 들어 PROPER("abCdE") 는 Abcde입니다. 단어의 첫째 문자가 영문자가 아닌 경우, 영문자가 아닌 문자 다음에 오는 영문자를 대문자로 ...