엑셀 / 함수 / DELTA / 두 숫자가 같은지 비교하는 함수
개요
DELTA는 두 수가 같은지 비교하는 함수입니다.
구문
DELTA(number1, [number2])
- number1 : 필수 요소로, 숫자입니다.
- number2 : 선택 요소로, 숫자입니다.
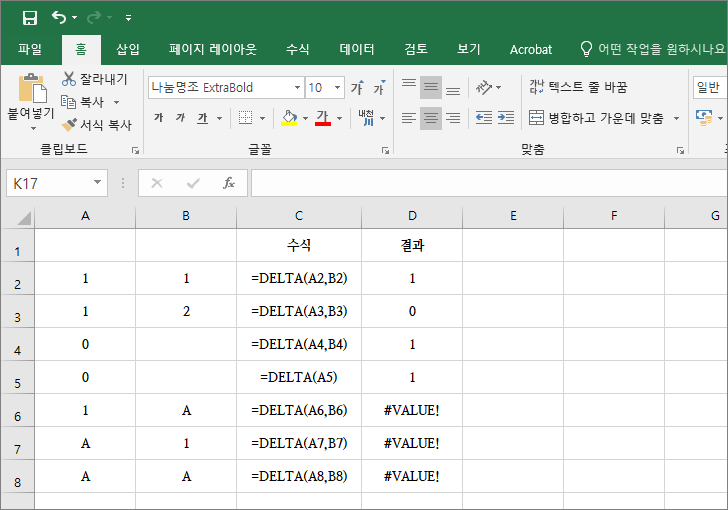
두 수가 같으면 1을, 다르면 0을 반환합니다.
두 번째 인수를 생략하면 0으로 간주합니다. 예를 들어 DELTA(0)은 1이고, DELTA(1)은 0입니다.
참조하는 셀이 비어있으면 0으로 간주합니다.
인수에 숫자가 아닌 값이 있으면 #VALUE! 오류 값이 반환됩니다.
예제
엑셀 / 삼각함수(사인, 코사인, 탄젠트 등)의 값 계산하기
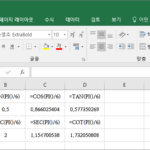
개요 삼각함수에는 사인 함수, 코사인 함수, 탄젠트 함수, 코시컨트 함수, 시컨트 함수, 코탄젠트 함수가 있습니다. 엑셀에서 각 함수의 값을 구할 수 있는데, 함수 이름이 삼각함수의 표기법과 같습니다. 예를 들어 사인은 sin으로 나타내는데, 사인 값을 구하는 엑셀 함수도 SIN입니다. 구문 사인 함수 SIN(number) 코사인 함수 COS(number) 탄젠트 함수 TAN(number) 코시컨트 함수 CSC(number) 시컨트 함수 SEC(number) 코탄젠트 함수 COT(number) 각도의 단위 number에는 각도를 입력하는데, 단위는 라디안입니다. 45도에 대한 ...
보기 좋게 표를 만들거나 보고서를 만들려면 셀들을 합쳐야 할 때가 있습니다. 엑셀에서는 셀을 합치는 것을 병합이라고 하고, 다시 나누는 것을 분할이라고 합니다. 어떻게 병합하고 분할하는지, 병합에는 어떤 방법이 있는지 알아보겠습니다. 병합하고 가운데 맞춤 셀을 합치는 가장 간단한 방법은 합치려는 셀들을 선택하고 을 클릭하는 것입니다. 셀들이 하나도 합쳐지고, 텍스트는 가운데 정렬합니다. 셀 병합을 하면 ...
엑셀 / VBA / 여러 시트의 내용을 하나의 시트에 모으는 방법
동일한 형식에 내용만 다른 여러 시트의 데이터를 하나로 합치는 방법을 알아본다. 예를 들어 다음과 같은 엑셀 문서가 있다고 하자. 첫 번째 시트는 합쳐진 데이터가 모일 시트이고, 나머지 세 개는 데이터가 있는 시트이다. 을 클릭한다.(만약 개발 도구 메뉴가 없다면 여기의 안내대로 개발 도구를 추가한다.) 을 클릭한다. 다음과 같이 코드를 입력한다. Sub Merge() ...
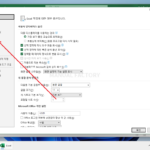
엑셀에서 작업 후 저장할 때 여러 가지 형식의 파일로 저장할 수 있다. 기본값은 보통 인데... 로 설정 매크로를 많이 사용하여 기본 저장 파일 형식을 로 기본값을 설정 하고 싶을 수 있다. 이러한 설정은 에서 한다. 왼쪽에서 을 클릭한다. [다음 ...
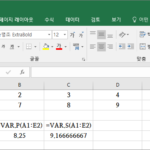
엑셀 / 함수 / VAR.P, VAR.S, VARP, VAR / 분산과 표본분산 구하는 함수
개요 VAR.P는 분산을 구하는 함수입니다. 엑셀 2007 이전 버전이라면 VARP 함수를 사용합니다. VAR.S는 표본분산을 구하는 함수입니다. 엑셀 2007 이전 버전이라면 VAR 함수를 사용합니다. 구문 분산을 구하는 구문은 다음과 같습니다. VAR.P(number1,,...) 표본분산을 구하는 구문은 다음과 같습니다. VAR.S(number1,,...) 예제 다음은 같은 자료로 분산과 표본분산을 구하는 예제입니다. 표본분산이 좀 더 크게 나와야 정상입니다.
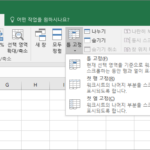
틀 고정 엑셀에 데이터를 입력할 때 보통 표 형태로 넣습니다. 첫 행에 제목을 넣고 밑으로 주욱 입력하거나, 첫 열에 제목을 넣고 오른쪽으로 주욱 입력을 하죠. 자료가 많다면 입력한 내용이 한 화면에 다 나오지 않습니다. 그 보이지 않는 부분을 볼려면 아래로 또는 오른쪽으로 스크롤해야 하는데, 그럴 경우 제목 행 또는 제목 열이 안보여서 ...
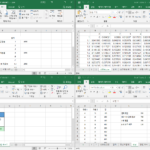
여러 워크시트 동시 작업 여러 워크시트에서 동시에 작업할 때가 있습니다. A 시트에서는 데이터를 관리하고, B 시트에서는 그 데이터를 분석하고... 작업을 하면서 여러 시트를 왔다갔다 하는 게 많이 불편합니다. 그럴 땐 한 화면에서 여러 시트를 한 번에 볼 수 있게 만들면 좋습니다. 시트간 이동도 편하고, 한 눈에 모든 걸 볼 수 있는 것도 ...
개요 ABS 함수는 'absolute value'의 약자로, 숫자의 절댓값을 구하는 함수입니다. 절댓값은 숫자의 크기만을 나타내며, 부호를 무시합니다. 예를 들어, -5의 절댓값은 5이고, 5의 절댓값은 그대로 5입니다. 구문 ABS(number) number: 절댓값을 구하고자 하는 숫자입니다. 이 인수는 숫자 자체일 수도 있고 셀 참조나 수식의 결과일 수도 있습니다. 예제 기본 예제 절댓값을 구하고자 하는 숫자를 직접 함수에 입력하는 방법입니다. 다음은 25를 반환합니다. =ABS(-25) 다음은 ...
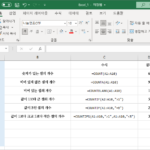
엑셀 / 함수 / COUNT, COUNTA, COUNTBLANK, COUNTIF, COUNTIFS
개요 셀 개수를 세는 함수에는 COUNT, COUNTA, COUNTBLANK, COUNTIF, COUNTIFS가 있다. COUNT는 숫자가 있는 셀의 개수, COUNTA는 비어 있지 않은 셀의 개수, COUNTBLANK는 비어 있는 셀의 개수, COUNTIF는 조건에 맞는 셀의 개수, COUNTIFS는 여러 조건에 맞는 셀의 개수를 반환한다. 구문 COUNT COUNT(value1, , ...) 숫자가 있는 셀의 개수를 반환한다. 비어 있거나 문자가 있는 셀은 세지 않는다. COUNTA COUNTA(value1, , ...
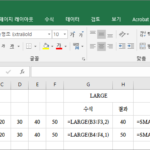
엑셀 / 함수 / LARGE, SMALL / k번째로 큰 값, 작은 값 구하는 함수
개요 LARGE는 데이터 집합에서 k번째로 큰 값을 반환하는 함수입니다. SMALL은 데이터 집합에서 k번째로 작은 값을 반환하는 함수입니다. 구문 LARGE(array,k) SMALL(array,k) array : 필수 요소로, 데이터 집합입니다. k : 필수 요소입니다. 몇 번째로 큰 값 또는 작은 값을 찾을지 정합니다. 예제 예제 1 10, 20, 30, 40, 50 중에서 2번째로 큰 값 또는 작은 값을 구합니다. 예제 2 10, 20, 30, 40, 50 중에서 첫 ...