엑셀 / 함수 / TEXTJOIN / 여러 텍스트를 하나로 합치는 함수
개요
- TEXTJOIN은 여러 문자열을 합하여 하나의 문자열로 만드는 함수입니다.
- CONCAT과 비슷하나, 구분 기호와 빈 셀 처리에 대한 설정이 가능합니다.
구문
TEXTJOIN(delimiter, ignore_empty, text1, [text2], …)
- delimiter : 문자열 사이에 들어갈 구분 기호입니다.
- ignore_empty : 빈 셀을 무시할지 정합니다. TRUE면 무시하고, FALSE면 무시하지 않습니다.
- text1 : 연결할 텍스트 항목입니다.
- text2 : 연결할 추가 텍스트 항목입니다.
예제
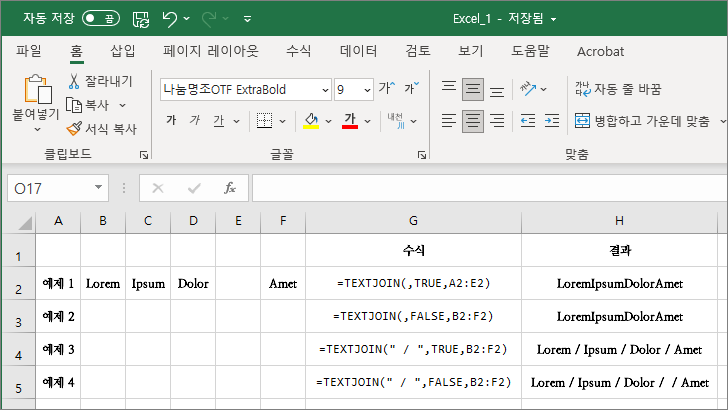
예제 1
- 구분 기호 없이, 빈 셀을 무시하고 문자열들을 합칩니다.
예제 2
- 구분 기호 없이, 빈 셀을 포함하여 문자열들을 합칩니다.
- 구분 기호가 없으므로 예제 1과 결과가 동일합니다.
예제 3
- 구분 기호로 /를 사용하고, 빈 셀을 무시하고 문자열들을 합칩니다.
예제 4
- 구분 기호로 /를 사용하고, 빈 셀을 포함하여 문자열들을 합칩니다.
- 구분 기호가 있으므로 빈 셀이 있다는 것을 확인할 수 있습니다.
기타
결과 문자열이 32767자를 초과하면 #VALUE! 오류가 반환됩니다.
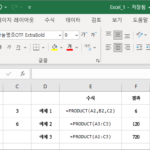
개요 PRODUCT는 곱을 구하는 함수이다. 곱은 *를 이용하여 구할 수도 있으나, 곱할 값들이 많으면 PRODUCT가 편하다. 구문 PRODUCT(number1, , ...) number1 : 필수 요소로, 곱하려는 첫 번째 숫자 또는 범위 number2, ... : 선택 요소로, 곱하려는 추가 숫자 또는 범위 최대 255개의 인수를 곱할 수 있다. 예제 예제 1 값을 지정하여 세 개의 값을 곱한다. 다음과 같은 결과를 얻는다. =A2*B2*C2 예제 2 범위를 ...
엑셀 / 함수 / UPPER, LOWER, PROPER / 대문자로 또는 소문자로 변환하는 함수
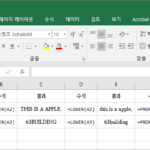
개요 UPPER, LOWER, PROPER는 대문자 또는 소문자 변환과 관련된 함수입니다. UPPER : 모두 대문자(upper case)로 바꿉니다. LOWER : 모두 소문자(lower case)로 바꿉니다. PROPER : 단어의 첫글자는 대문자로, 나머지는 소문자로 바꿉니다. 구문 UPPER(text) LOWER(text) PROPER(text) text : 필수 요소로, 대문자로 또는 소문자로 변환할 텍스트입니다. PROPER 함수 단어의 첫째 문자를 대문자로 변환하고, 나머지 문자들은 소문자로 변환합니다. 예를 들어 PROPER("abCdE") 는 Abcde입니다. 단어의 첫째 문자가 영문자가 아닌 경우, 영문자가 아닌 문자 다음에 오는 영문자를 대문자로 ...
엑셀 / 함수 / SUMSQ / 제곱의 합 구하는 함수
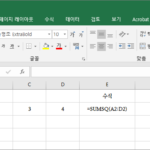
개요 SUMSQ는 제곱의 합을 구하는 함수입니다. 구문 SUMSQ(number1, , ...) number1, number2, ... : number1은 필수 요소이고, 이후의 number는 선택 요소입니다. 인수는 255개까지 넣을 수 있습니다. 예제 1부터 4까지 제곱의 합을 구합니다.
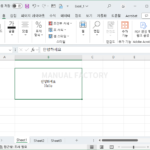
셀 안에서 줄바꿈을 하고 싶다면 Alt + Enter를 누릅니다. 줄바꿈한 내용을 수식입력줄에서 보고 싶다면, 오른쪽 끝에 있는 아이콘을 클릭합니다.
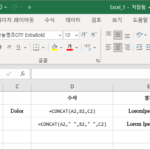
엑셀 / 함수 / CONCAT, CONCATENATE / 여러 텍스트를 하나로 합치는 함수
개요 CONCATENATE는 여러 문자열을 하나의 문자열로 합하는 함수입니다. Excel 2016, Excel Mobile 및 Excel Online에서는 이 함수가 CONCAT 함수로 대체되었습니다. 이전 버전과의 호환성을 위해 CONCATENATE 함수도 계속 제공되지만 CONCAT을 사용하는 것이 좋습니다. TEXTJOIN 함수를 이용하면 구분 기호 설정을 쉽게 할 수 있고, 빈 셀에 대한 처리 방법도 정할 수 있습니다. 구문 CONCAT(text1, , ...) text1 : 필수 ...
엑셀 / 피벗 테이블 / 여러 범위로 다중 피벗 테이블 만드는 방법
피벗 테이블은 보통 하나의 범위 또는 표로 만듭니다. 따라서 여러 개의 범위 또는 표로 피벗 테이블을 만들기 위해서는 하나로 합치는 과정을 거치는데, 그 과정이 번거롭다면 여러 범위(다중 통합 범위)로 피벗 테이블을 만들 수도 있습니다. 어떤 방식이 편한지는 데이터에 따라 다르겠죠. 피벗 테이블/피벗 차트 마법사 메뉴 추가 다중 통합 범위 피벗 테이블을 만들기 ...
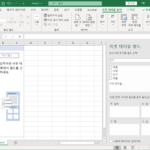
엑셀 / 피벗 테이블 / 외부 파일 시트의 데이터로 피벗 테이블 만드는 방법
엑셀의 피벗 테이블은 데이터 분석을 위한 유용한 기능입니다. 피벗 테이블은 보통 같은 파일 내에서 같은 시트 또는 다른 시트에 만들게 되는데, 다른 파일에 있는 데이터로 피벗 테이블을 만들 수도 있습니다. 어떻게 만드는지 그 방법을 알아보겠습니다. 예제 파일 다음과 같은 내용의 Excel_1 파일이 있습니다. 데이터는 표로 지정되었습니다. 이를 Excel_2 파일에 피벗 테이블을 만들 ...
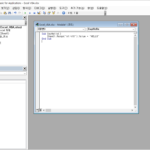
간단한 예제로, VBA로 매크로를 만들고 실행하는 과정을 살펴보겠습니다.(개발 도구 메뉴가 없는 경우 옵션 변경으로 추가할 수 있습니다.) 을 클릭합니다.(단축키는 Alt+F11입니다.) 다음과 같은 에디터 창이 나오는데... 을 클릭합니다. 코드를 넣을 수 있는 창이 나오는데... 다음 코드를 입력합니다. Sub SayHello() Sheet1.Range("A1").Value = "HELLO" End ...
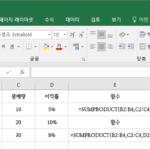
엑셀 / 함수 / SUMPRODUCT / 곱의 합 구하는 함수
개요 SUMPRODUCT는 곱들의 합을 구하는 함수이다. 이것을 주어진 배열에서 해당 요소를 모두 곱하고 그 곱의 합계를 반환한다고 표현한다. 표현은 복잡하지만, PRODUCT를 구하고 그 다음 SUM을 구한다고 생각하면 된다. 구문 SUMPRODUCT(array1, , ...) 각 배열에 같은 순서에 있는 값들을 곱한 후 다 더한 값을 출력한다. 배열 안의 값의 개수, 즉 차원이 같아야 한다. 만약 다르면 #VALUE! ...
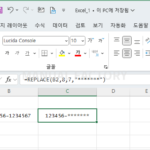
예를 들어 B2 셀에 있는 주민등록번호의 뒷자리를 별표로 바꾸고 싶다면 다음과 같이 합니다. =REPLACE(B2,8,7,"*******")